It’s an open secret that the CSA mandelbrot benchmark tool (available in my ‘basic Transputer tools‘ package) is one of my favorite benchmark and test-tool when playing around with my various Transputer toys.
One fine day I thought VGA with more than 16 colo(u)rs would be nice… and the coding began. First step: Put the original source (well, already enhanced by a timer and some debugging) on github.
The original CSA Mandel program uses the official 640×480 16 color VGA mode (aka 0x12) and uses its own calls for that, i.e. no external 3rd party libs. Very manly 😉 but not very colorful…
So I created the first branch (aka Mandel_3) added a more “modern” command-line options handling and dived into hand-coding VBE (VESA BIOS Extensions) matters. That was very instructive and fun… and the first results showed that I didn’t just got 256 colors now but draw speed was increased, too 😯
Look Mom! More colors:
Running in host-mode (/t) on my P200MMX the initial screen took 6.6s vs 7.1s for 16-colors – so a difference of 0.5s or 7% should be much higher on Transputers, so I thought. And should this mean that bigger Transputer farms had been bottleneck’ed by the actual plotting of pixels?
Because 256 colors and higher resolutions (up to 1280×1024 depending on your VGA cards VESA BIOS) are fine, but even more colors are better, I branched the code a 2nd time (MANDEL_BGI) and replaced the VBE code by a BGI SVGA interface.
While originally Borland only supports VGA, there are 2 BGI drivers written by 3rd party developers which do support SVGA and up to 24-bit colors.
It’s commonly known that BGI is not the fastest graphics interface on planet earth… and the benchmark proved this:
P200MMX
Orig
VESA
SVGA
SVGA256
1
7.123
6.623
8.911
6.915
2
38.258
36.635
39.717
37.725
I was hoping the change would have more impact when running the same on my Cube system… well it didn’t:
65x T800 (integer)
Orig
VESA
SVGA
SVGA256
1
2.323
2.288
3.940
2.383
2
8.163
8.173
8.181
8.164
So as final conclusion, I will stay with the VBE SVGA drivers included in the V3.x code – it’s a good compromise between overall code/distribution size, comfort and speed.
The original VGA mode (0x12) will stay in the code forever to get comparable benchmark measurements – if you really need CGA/EGA/Hercules, you can always use the 2.x version.
As soon you’re talking about Transputers with people which weren’t there back in 1985 you’ll be asked this very soon: “How fast are these Transputer thingies”? Then there’s a stakkato of “MIPS? Whetstones? Dhrystones?” etc…
As always with benchmarks, the only valid answer is “it depends”. Concerning Transputers that’s even more true.
First, I suggest you read this Lies, Damn lies and benchmarks document from INMOS itself. It pretty much describes the dilemma and all the smoke and mirrors around that matter.
Benchmarks? It depends.
So you’ve read the above INMOS document? As you might saw, it’s full of OCCAM code. That’s the #1 prerequisite to get fast, competitive code (as long you’re not into Transputer assembler). From there it gets worse if you use a C compiler or even FORTRAN…
My little benchmark
Because it scales so well, works with integer as well as floating point CPUs and also runs on the x86 host while using at least the same graphic output routines, my personal benchmark is CSAs Mandelbrot tool (DOS only).
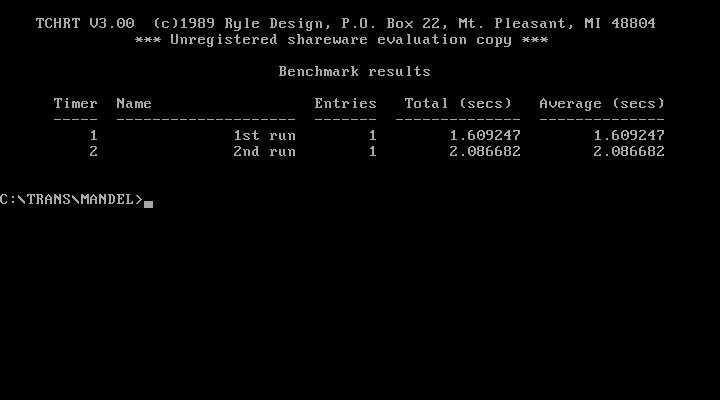
My slightly modified version is part of my Transputer Toolkit, which is downloadable here. You will need that version because I extended the code of this Mandelzoom with a high precision timer (TCHRT, shareware, can’t remove the splashscreen, sorry) when run with the “-a” parameter. You’ll need my provided default “MAN.DAT” file, which contains 2 coordinates to calculate (1st & 2nd run) to get comparable numbers.
So to bench your Transputer system start it with:
man -v -a
which runs it in VGA mode (640x480x16c), loads the coordinates from “MAN.DAT” and when done presents you with a summary screen like this:
To run it on your hosts x86 CPU, call it with “man -t -v -a”
The Results
Here are my results of the different Mandelzoon runs I made in the past. The blue background marks the host machine results, yellow are the integer timings and green is where the mucho macho things are happening.. well, sort of 😉
There are two columns for the results, the HD timer and the hand-timed runtimes. This is because these are from days before I enhanced the Mandelzoom.
This table will continously updated of course. e.g. the last row is pretty new – what might that system be? 😯
The sources are available in my github repository – so we can collaborate on enhancing and optimizing it.
HD in-programm Timer (s)
Hand-Timed
System
1st
2nd
1st run
2nd run
Comment
i386DX/33 (0kb L2)
1800
0
1:30:00
(canceled)
0
Canceled 1st run after a quarter of Mandelbrot was done…
i386DX/33 (0kb L2) + 387
588
3316
0:09:48
0:55:16
Am386/40 (0kb L2) + 387
490
2980
0:08:10
0:49:40
21% faster clock but only 10.5% better result
i386DX/33 (128k L2) + 387
274
1547
0:04:34
0:25:47
Am386DX/40 (128k L2) + 387
228
1292
0:03:48
0:21:32
i486DX/33 (8k L1, 0k L2)
01:06.24
368.56
Pretty close to a single T800-20
i486DX2/66 (8k L1, 128k L2)
00:33.72
185.51
Very close to 2x T800-20
Pentium 133 (256kb L2)
00:09.09
00:55.01
About 8x T800-20
Pentium 200 MMX
00:07.13
00:38.06
About 9x T800-20
AMD K6-3+/266
00:06.00
00:32.00
Downclocked, 64k L1, 256kb L2, 1M L3
Core i3-2120 3.3GHz
00:01.66
00:02.13
VirtualBox,1 CPU
1x T425-20
0:00:25
0:02:28
There’s something wrong here – needs re-run
2x T425-20
00:51.55
04:56.60
3x T425-20
00:34.42
03:17.81
4x T425-20
00:25.86
02:28.56
5x T425-20
00:20.74
01:58.96
6x T425-20
00:17.37
01:39.19
9x T425-20
11
62
0:00:11
0:01:02
13x T425-20
8
42
0:00:08
0:00:42
21x T425-20
5
27
0:00:05
0:00:27
25x T425-20
4
23
0:00:04
0:00:23
65xT425 (48x25Mhz, 16x20MHz)
00:02.323
00:08.163
Actually it was 64xT800 and one T425 forcing the calculation to integer
1x T800-20
01:09.13
06:27.18
1x T800-25
0:00:55
0:05:09
25% higher clockrate should result in 17.5% speedup. Incl comm-overhead that pretty much fits
1x T800-30
00:00.46
00:04.30
2x T800-20
00:35.65
03:13.79
3x T800-20
00:23.16
02:09.32
4x T800-20
00:17.43
01:37.04
5x T800-20
00:14.04
01:17.74
6x T800-20
00:11.82
01:04.83
5x T800-25
11
62
0:00:11
0:01:02
9x T800-20
8
40
0:00:08
0:00:40
13x T800-20
5
30
0:00:05
0:00:30
17x T800-25
00:03.8
00:18.59
“1st run” shows that the slow ISA interface is really getting a bottleneck
So after the lengthy description of the DSM cards – how can we make use of them? As said in the previous chapter, they were shipped with an assembler and even an early version of GCC (1.3) so development is pretty straightforward.
Activation
First, you have to understand how the cards integrate themselves into an ISA/EISA system. While the three versions (8, 16, 32bit) differ in some areas, the integration is more or less similar:
Each version offers a latch for controlling the card. This means to activate the card by writing bits to that latch to define a memory-window inside the hosts RAM to blend-in the cards dual-ported RAM and/or resetting it etc.. The latch is accessible through an IO-port set by jumpers on the card (default 0x300).
So for the ISA cards you have to for example write a 0xC2 at that port-adress to reset & activate the card and use the mem-window of 0xDC000-DC7FF. In Turbo-Pascal this would be something like:
port[$300] := $c2;
This gives you a 2K mem-window to exchange data between the DSM and the host (just 1K for the DSM860-8).
The EISA cards obviously use other ports depending on the slot-number, so this would be an example to do the same for am DSM860-32, this time in Turbo-C:
outportb(slot_no * 0x1000 + 0x800, 0xc2); // For slot #2 this would be 0x2800
This would also open a mem-window at 0xDC000, this time up to 0xDCFFF, i.e. 4K long.
Memory
As mentioned above, the Host and the DSM-card are communicating through a memory-window of diffenrent sizes, depending on the DSM used. Due to their nature, the memory is looking different though. That said, at least they’re both litte-endian, so no byte-swapping needed.
The 80×86 side
For the hosting PC, memory looks pretty straightforward. 1KB-4KB of RAM somewhere in ‘lower-RAM’, that’s it.
While we don’t use it, it’s worth mentioning that there’s a 2nd memory window called “Common“. This is fixed at a specific address and is shared between all possible cards plugged into one host. I guess you already got it: This enables easy multi-processor communication… and gives a lot of possibilities for f**k-ups.
The i860 side
The memory-mapping on the i860-side is the same for the 16 and 32bit cards, the dual-ported RAM is located at 0xd0040000 (0xC0000000 for the DSM-8).
In any case the i860 memory is linear, 64bit wide and always on a 64-bit boundary. This means you have to read the DP-RAM area differently depending on which card you run your code. Here’s an example of how the DP-RAM looks like on the Host- and i860 side:
Host DP-RAM in DOS ‘debug’ -d dc00:0000 DC00:0000 11 22 33 44 55 66 77 88 ...
which would look like this on the i860 side:
DSM/8 C0000000 - 11 xx xx xx xx xx xx xx 22 xx xx xx xx xx xx xx C0000010 - 33 xx xx xx xx xx xx xx 44 xx xx xx xx xx xx xx C0000020 - 55 xx xx xx xx xx xx xx 66 xx xx xx xx xx xx xx C0000030 - 77 xx xx xx xx xx xx xx 88 xx xx xx xx xx xx xx
DSM/16 D0040000 - 11 22 xx xx xx xx xx xx 33 44 xx xx xx xx xx xx D0040010 - 55 66 xx xx xx xx xx xx 77 88 xx xx xx xx xx xx
DSM/32 D0040000 - 11 22 33 44 xx xx xx xx 55 66 77 88 xx xx xx xx
So reading and writing from/to the DP-RAM involves some thinking to be done by the programmer. Here are two code-snippets showing the difference between reading the DP-RAM on a DSM860-8 and an DSM860-16. First the ‘8 bit version’:
mov 4*8,r4 readloop: ld.b 0(r15),r14 // Load BYTE from DP-RAM st.b r14,0(r29) // store it destination addu 8,r15,r15 // add 8 to read-mem-pointer addu 1,r29,r29 // add 1 to desitination-mem-pointer addu -1,r4,r4 // loop-counter xor r0,r4,r0 // Test Zero bnc readloop
And the same for the DSM860-16:
mov 2*8,r4 readloop: ld.s 0(r15),r14 // Load SHORT (2 Bytes) from DP-RAM st.s r14,0(r29) // store it destination addu 8,r15,r15 // add 8 to read-mem-pointer addu 2,r29,r29 // add 2(!) to desitination-mem-pointer (short <> byte) addu -1,r4,r4 // loop-counter xor r0,r4,r0 // Test Zero bnc readloop
Because of reading SHORTs (ld.s) the DSM860-16 version has to loop just 16 times while the 8-bit version has to do that 32 times.
Same applies to writing. You will find an example in the Mandelbrot program (Commented source file).
[This is work-in-progress and will expanded over time]
Action!
So here we go, finally some program running showing all the power behind the i860. I took the Mandelbrot example from R.D.Klein and modified it a bit, well quite a bit as it was written for the DSM860-8 and provided CGA output (yuck!).
Like most “external accelerator” programs, there’s one part running on the accelerator (the i860 in this case) and one part running on the host doing useful things with the provided data. In this case we have an i860 assembler code doing the number-crunching on the Mandelbrot algorithm using the i860’s ability of ‘dual instruction-mode‘ and some code done in Trubo-Pascal handling the display and zooming.
The latter was extended to use SVGA (640x480x256) output and providing an interrupt driven timer. [sourcecode package cleanup is still work in progress]
Here are the two running full steam ahead:
Some things worth to mention:
The host being used here is a P1 133MHz, a bit unfair comparing that to a 40MHz i860 – OTOH they seem quite comparable when it comes down to Mandelbrot crunching speed.
To calculate the Mandelbrot the same speed as it took the Pentium (~15s) I needed five T800-20 according to my benchmarks.
To even achieve the 8.2s of the i860 I had to run 9(!) T800-20 in parallel.
A i486DX/33 took 66 sec to do the same (8.25 times slower!), while it still took 34s for a i486DX2/66!
So while all that moaning about the bad ‘programmability’ and slow context-changes of the i860 are completely correct, in certain tasks that CPU was indeed a real screamer!
Like with the C64, this is probably the reason you came here:
The friggin’ fastest Mandelbrot displayed on a IIgs, ever! 😉
Yeah, you’re right, it’s not the fastest Mandelbrot calculated by an IIgs (its very own 65c816 CPU, that is)… but hey, it’s still kinda cool – and sooooo much faster!
Okey-Dokey, here we go, a complete Mandelbrot in 60s. This time in color… and zooming in! I couldn’t do that on the C64 as the C-Compiler didn’t natively support IEEE754 doubles (like Orca-C does) and having a mouse also helps a bit, too:
Wow, that was nice, wasn’t it?! (Sorry for the shaking, need to get a tripod soon)
Especially when you take in concern how ‘far’ the native 65c816 code got during the video on a ‘sped-up’ 10MHz TransWarp GS.
Like with the T2C64 version there are surely several things which could be improved, but the IIgs (even at native speed) is well capable to handle the little bit of extra work. The limiting factor is the bus-speed, i.e. how quick the Transputer can push his data into the host (IIgs). You can clearly see that by the time it took the display the 3 zooms: They all took about 60 seconds, even each zoom means more calculations as the iteration is doubled each zoom, in this case 32, 64, 128.
The Orca-C source/binary of this demo -and the previous AppleSoft sample- is available here (zip’ed PRODOS disk-image). It won’t make much sense without a T2A2 and is GS/OS-only as it uses QuickDraw II and the EventManager (for mouse & keyboard).
Final words: Don’t get too excited about the acceleration of the IIgs… it’s not accelerated at all. It’s more like a co-processor attached to it. And even then, you’ll need something really calculation-intensive to justify the time you’ll loose due to communication between the Apple and the Transputer. A single square-root for example wouldn’t make much sense.
But OTOH, that’s exactly things are handled with the Innovative Systems FPE (using a M68881). So it might be worth evaluating. Maybe I’ll write a SANE driver if I have the time to get a deeper understanding of GS/OS.
As my two targets (C64 & Apple II) are working now, I’m thinking about creating a ‘real PCB’ in the medium term. Given the rarity of the Link-Adaptor (Inmos C012) I’m currently looking into the possibility to use a larger CPLD to move the C012 into that. This would actually make this ‘project’ a product to buy. But don’t hold your breath, need to get an eval kit first. Then some 100 days of fiddling, cursing and crying… and then more.
Like with the T2C64, the CPLD on the T2A2 maps the C012 registers into the memory area of the used slot, using just 6 addresses starting at 0xc080 + (SLOT# * 0x10). So for e.g. Slot 4 this would be:
BASE (0xc080 + (4 * 0x10)) = 49344
Data in: BASE 49344
Data out: (BASE + 1) 49345
in-status: (BASE + 2) 49346
out-status:(BASE + 3) 49347
reset: (BASE + 8) 49352 (writing)
analyse: (BASE + 12) 49356
errorflag: (BASE + 8) 49352 (reading)
With this ‘knowlege’ we can start talking to the Transputer… and to make our first babysteps we’re using BASIC. It’s pretty much the same code as used on the C64 with the exception that there’s no “elegant” timeout handling due to the missing clock in AppleSoft, so you have to wait a bit longer until you get the printout in the end.
For details about what’s going on here, see the C64 page.
10 PRINT "INIT TRANSPUTER"
11 BASE = 49344:IN = BASE:OUT = BASE + 1:IS = BASE + 2
12 OS = BASE + 3:RESET = BASE + 8:ANA = BASE + 12
13 POKE RESET,0: POKE ANA,1: POKE RESET,1
20 REM CLEAR I/O ENABLE
21 POKE IS,0
22 POKE OS,0
30 REM READ STATI
31 PRINT "I STATUS: ";( PEEK (IS) AND 1)
35 PRINT "O STATUS: ";( PEEK (OS) AND 1)
40 PRINT "ERROR: ";( PEEK (RESET) AND 1)
45 PRINT "SENDING POKE COMMAND"
46 POKE OUT,0
50 PRINT "O STATUS: ";( PEEK (OS) AND 1)
58 :
59 PRINT "SENDING DATA TO T."
60 POKE OUT,0: POKE OUT,0: POKE OUT,0: POKE OUT,128
61 POKE OUT,12: POKE OUT,34: POKE OUT,56: POKE OUT,78
70 PRINT "I STATUS: ";( PEEK (IS) AND 1)
79 :
80 PRINT "READING FROM T."
90 POKE OUT,1: REM PEEKING
100 POKE OUT,0: POKE OUT,0: POKE OUT,0: POKE OUT,128
110 PRINT PEEK (IN); PEEK (IN); PEEK (IN); PEEK (IN)
128 DIM R(4)
129 PRINT "SENDING PROGRAM TO TRANSPUTER..."
130 FOR X = 1 TO 24
140 READ T: POKE OUT,T
150 WAIT OS,1
160 NEXT X
170 PRINT : PRINT "READING RESULT:"
175 C = 0: REM RETRIES
180 IF C = 10 GOTO 220
181 FOR X = 0 TO 5000: NEXT X: REM DELAY
189 ER = ER + 1: IF ER = 10 GOTO 220
190 IF ( PEEK (IS) AND 1) = 0 GOTO 181
195 R(C) = PEEK (IN)
200 C = C + 1:ER = 0
210 GOTO 180
211 REM ------------------------
220 IF C = 1 THEN PRINT "C004 FOUND"
230 IF C = 2 THEN PRINT "16 BIT TRANSPUTER FOUND"
240 IF C = 4 THEN PRINT "32 BIT TRANSPUTER FOUND"
250 IF C = 0 OR C > 4 THEN PRINT "COULD NOT IDENTIFY""
1000 DATA 23,177,209,36,242,33,252,36,242,33,248
1001 DATA 240,96,92,42,42,42,74,255,33,47,255,2,0
Ok, if this is running fine, i.e. a Transputer was actually found and your Apple didn’t went up in smoke, we’re set for some serious numbercruncing… and a video! Yay! We love Videos, don’t we?
And now something which you knew it would come: Mandelbrot time! 😉
I don’t want to bore you with all the details before you had it seen in action… so here we go:
“Man, that was brilliant! And even you had a lot of geek-babble in there, I want to know more!”
Ok Timmy, let’s go into detail…
Like I said in the video, the Transputer is finally doing something for real, he’s actually doing the most of the work, crunching through a 320x200x8 Mandelbrot, 32 iterations in double-precision floating point. The code itself was written 1988 in OCCAM by Neil Franklin and is available on his page.
This shows the general beauty of Transputers: If the code is written flexible enough to fit into any topology, it’ll run on any platform!
That said, I ran into a certain limitation on the C64. The Transputer mandelbrot executable expects the initial data (resolution, coordinates, iterations) to be send in a specific order and format. While the order isn’t the problem, the format is: The coordinates have to be doubles (C-lingo i.e. 64bit IEEE 754 compliant float). The C-Complier I’ve used for this demo (CC65) doesn’t now a flying s*** about floats or even doubles.
So to get that demo done ASAP I tricked myself a bit and used the same technique we’ve seen in my 1st demo when POKEing something the Inmos-way:
To get the coordinates for left (-2.0), right (1.0), top (1.125) and bottom (-1.125) over to the Transputer they had to be converted into 64bit IEEE 754 format, ordered into little-endianess and finally put into an array like these:
Yes, that’s a bit awkward, but it was OK to get a fast start. The ‘problem’ with this quick-hack is that the demo is pretty static, i.e. no zooming into the Mandelbrot. If you know of a quick way to create IEEE 754 compliant doubles from a long (which is the biggest floating point variable CC65 can handle, so StringToDouble() isn’t an option here) I’m happy to hear from you.
Of course I could have the Transputer do the typecasting but in this case, as part of a demo, I wanted to keep the original binary untouched.
In the video you saw (or didn’t because of the blurry picture) that the timer printout was about 70s… and as said, normally it takes about 60s to complete the fractal – and it did in the video, too! Watch the video-timer or check with a stopwatch. What I’ve forgot to take out from the timing was the actual upload of the code into the Transputer.
The Transputer binary is in this case a bigger array in the C-source, so it’s not being loaded from floppy but directly pushed to the Transputer after it was initialised. This takes some extra time which also went into the stopwatch timing… I’ll correct that in a later version.
“Later version” is a good catchword. If this wouldn’t be just a demo for now, there are obviously plenty of ways to optimise things:
First of all one should take off the burden of converting the colors from the C64 and let the Transputer do that.
My second idea would be to reduce the communication overhead (polling) by having the Transputer to render the whole screen into his own RAM and when done have it ‘pumped’ down to the C64
Yes, DMA would be cool but that’s not possible (yet)
Ok, that’s about it for now. The T2C64 is still in its prototype stage and I can image many more cool things to add… but first I will have a ‘proper’ circuit board being made.
Final words: Don’t get too excited about the acceleration of the C64… it’s not accelerated at all. It’s more like a co-processor attached to it. And even then, you’ll need something really calculation-intensive to justify the time you’ll loose due to communication between the C64 and the Transputer. A single square-root for example wouldn’t make sense at all. 100 sqrts in one go would certainly do.
Of course adding another linkOut/In to the T2C64 to get more Transputers involved into the calculation would be the final step. This is planned for the next version of the hardware but the bigger part of the work would be a complete rewrite of the Mandelbrot code to have it broken down to parts being run in parallel on each Transputer… which closes the loop to today where programmers are trying to wrap their brains around multithreaded programming. 22 years after the first Transputer was released 😉
home of real men's hardware
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.