
As soon you’re talking about Transputers with people which weren’t there back in 1985 you’ll be asked this very soon: “How fast are these Transputer thingies”? Then there’s a stakkato of “MIPS? Whetstones? Dhrystones?” etc…
As always with benchmarks, the only valid answer is “it depends”. Concerning Transputers that’s even more true.
First, I suggest you read this Lies, Damn lies and benchmarks document from INMOS itself. It pretty much describes the dilemma and all the smoke and mirrors around that matter.
Benchmarks? It depends.
So you’ve read the above INMOS document? As you might saw, it’s full of OCCAM code. That’s the #1 prerequisite to get fast, competitive code (as long you’re not into Transputer assembler). From there it gets worse if you use a C compiler or even FORTRAN…
My little benchmark
Because it scales so well, works with integer as well as floating point CPUs and also runs on the x86 host while using at least the same graphic output routines, my personal benchmark is CSAs Mandelbrot tool (DOS only).
My slightly modified version is part of my Transputer Toolkit, which is downloadable here. You will need that version because I extended the code of this Mandelzoom with a high precision timer (TCHRT, shareware, can’t remove the splashscreen, sorry) when run with the “-a” parameter. You’ll need my provided default “MAN.DAT” file, which contains 2 coordinates to calculate (1st & 2nd run) to get comparable numbers.
So to bench your Transputer system start it with:
man -v -a
which runs it in VGA mode (640x480x16c), loads the coordinates from “MAN.DAT” and when done presents you with a summary screen like this:
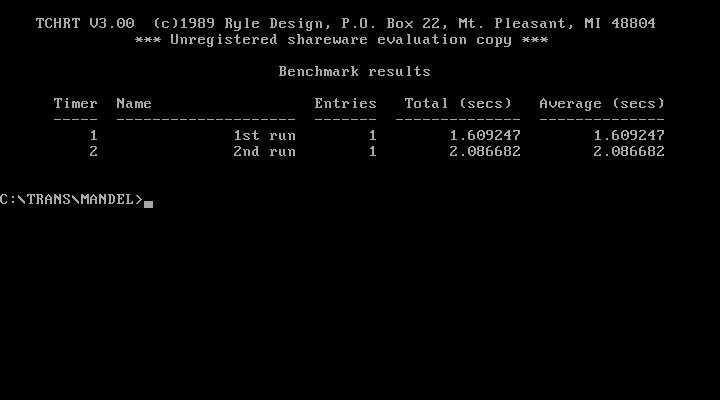
To run it on your hosts x86 CPU, call it with “man -t -v -a”
The Results
Here are my results of the different Mandelzoon runs I made in the past. The blue background marks the host machine results, yellow are the integer timings and green is where the mucho macho things are happening.. well, sort of 😉
There are two columns for the results, the HD timer and the hand-timed runtimes. This is because these are from days before I enhanced the Mandelzoom.
This table will continously updated of course. e.g. the last row is pretty new – what might that system be? 😯
The sources are available in my github repository – so we can collaborate on enhancing and optimizing it.
| HD in-programm Timer (s) | Hand-Timed | ||||
| System | 1st | 2nd | 1st run | 2nd run | Comment |
| i386DX/33 (0kb L2) | 1800 | 0 | 1:30:00 (canceled) |
0 | Canceled 1st run after a quarter of Mandelbrot was done… |
| i386DX/33 (0kb L2) + 387 | 588 | 3316 | 0:09:48 | 0:55:16 | |
| Am386/40 (0kb L2) + 387 | 490 | 2980 | 0:08:10 | 0:49:40 | 21% faster clock but only 10.5% better result |
| i386DX/33 (128k L2) + 387 | 274 | 1547 | 0:04:34 | 0:25:47 | |
| Am386DX/40 (128k L2) + 387 | 228 | 1292 | 0:03:48 | 0:21:32 | |
| i486DX/33 (8k L1, 0k L2) | 01:06.24 | 368.56 | Pretty close to a single T800-20 | ||
| i486DX2/66 (8k L1, 128k L2) | 00:33.72 | 185.51 | Very close to 2x T800-20 | ||
| Pentium 133 (256kb L2) | 00:09.09 | 00:55.01 | About 8x T800-20 | ||
| Pentium 200 MMX | 00:07.13 | 00:38.06 | About 9x T800-20 | ||
| AMD K6-3+/266 | 00:06.00 | 00:32.00 | Downclocked, 64k L1, 256kb L2, 1M L3 | ||
| Core i3-2120 3.3GHz | 00:01.66 | 00:02.13 | VirtualBox,1 CPU | ||
| 1x T425-20 | 0:00:25 | 0:02:28 | There’s something wrong here – needs re-run | ||
| 2x T425-20 | 00:51.55 | 04:56.60 | |||
| 3x T425-20 | 00:34.42 | 03:17.81 | |||
| 4x T425-20 | 00:25.86 | 02:28.56 | |||
| 5x T425-20 | 00:20.74 | 01:58.96 | |||
| 6x T425-20 | 00:17.37 | 01:39.19 | |||
| 9x T425-20 | 11 | 62 | 0:00:11 | 0:01:02 | |
| 13x T425-20 | 8 | 42 | 0:00:08 | 0:00:42 | |
| 21x T425-20 | 5 | 27 | 0:00:05 | 0:00:27 | |
| 25x T425-20 | 4 | 23 | 0:00:04 | 0:00:23 | |
| 65xT425 (48x25Mhz, 16x20MHz) | 00:02.323 | 00:08.163 | Actually it was 64xT800 and one T425 forcing the calculation to integer | ||
| 1x T800-20 | 01:09.13 | 06:27.18 | |||
| 1x T800-25 | 0:00:55 | 0:05:09 | 25% higher clockrate should result in 17.5% speedup. Incl comm-overhead that pretty much fits | ||
| 1x T800-30 | 00:00.46 | 00:04.30 | |||
| 2x T800-20 | 00:35.65 | 03:13.79 | |||
| 3x T800-20 | 00:23.16 | 02:09.32 | |||
| 4x T800-20 | 00:17.43 | 01:37.04 | |||
| 5x T800-20 | 00:14.04 | 01:17.74 | |||
| 6x T800-20 | 00:11.82 | 01:04.83 | |||
| 5x T800-25 | 11 | 62 | 0:00:11 | 0:01:02 | |
| 9x T800-20 | 8 | 40 | 0:00:08 | 0:00:40 | |
| 13x T800-20 | 5 | 30 | 0:00:05 | 0:00:30 | |
| 17x T800-25 | 00:03.8 | 00:18.59 | “1st run” shows that the slow ISA interface is really getting a bottleneck | ||
| 21x T800-20 | 4 | 18 | 0:00:04 | 0:00:18 | |
| 33x T800-20 | 00:02.88 | 00:11.97 | |||
| 65x T800 (32×25, 33x20Mhz) | 00:02.21 | 00:05.74 |